
Jakob Sverre Løvstad
CTO, Seema
9. februar 2026
En av de absolutt viktigste modellene for å forstå stereotypier og fordommer på en systematisk måte, er den såkalte «Stereotype Content Model», opprinnelig satt sammen av Fiske, Cuddy, Glick og Xu. Videre har den blitt testet ut og kartlagt i en rekke forskjellige kontekster – noe som er åpenbart viktig gitt at hvem man har stereotypier rundt og fordommer mot, varierer fra tidsfase til tidsfase og kultur til kultur (blant annet). Slike ting er alltid relativt.
Kort sagt sier modellen at alt vi mener om ymse grupper på et overflatenivå, kan sees som uttrykk for a) hvor varme/hyggelige/sosiale folk anses å være, og b) hvor mye kompetanse/hvor mye agens man anser at de har. Det er dette som enkelt forklart gir grupperinger status i andres øyne.
Akkurat for Norge har vi en oversikt over grupperinger og deres anseelse som stammer fra 2015 (dessverre ingen oppdateringer siden den tid):
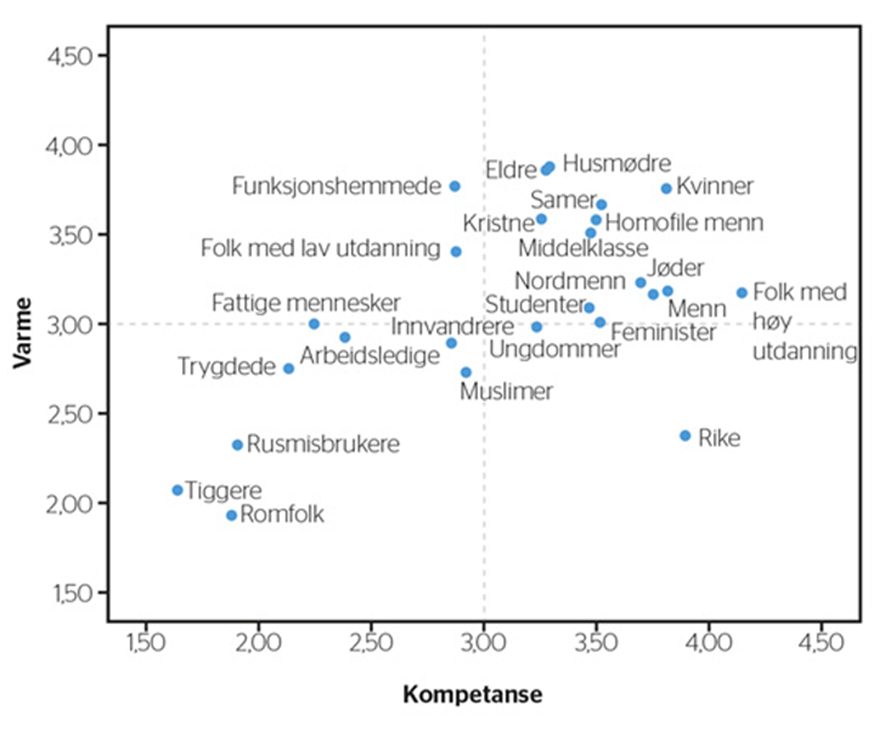
Det vi i mindre grad har belyst, er at det selvsagt er store variasjoner innad i disse gruppene for hvordan de anses. At eksempelvis «homofile menn» skårer godt (høy både varme og kompetanse), betyr ikke at alle skeive havner i samme bås. En nyere studie fra Sverige viser eksempelvis at både på eksplisitt (selvrapportering) og implisitt nivå («Implicit Association Test»; IAT), har vi en lik fordeling av forskjellige typer skeive (dog med litt forskjell i spredning) som tydeliggjør at man ikke ser subgrupper likt:
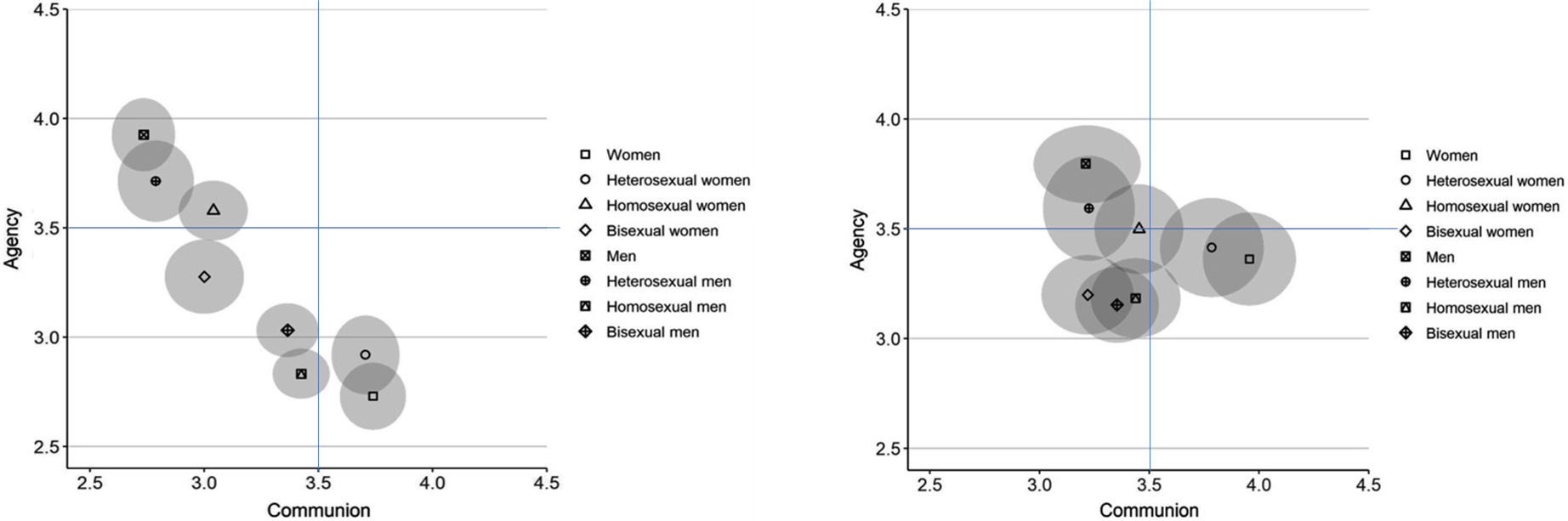
Som en fotnote er det interessant at det er en såpass stor forskjell på en del nevnte punkter mellom Norge i 2015 og Sverige i 2021. Det kan naturligvis skyldes en del forskjeller i seleksjon av deltagere til studien, men er likevel et tankekors.
I Sveits i 2024 gjorde man en liten studie på hvordan studenter ser på andre nasjonliteter, med følgende resultat, som også er interessant (merk at «Poor People», «Rich People», «Housewives» er ankere/avsjekker for å se at modellen generelt gjenspeiler andre studier av samme type):
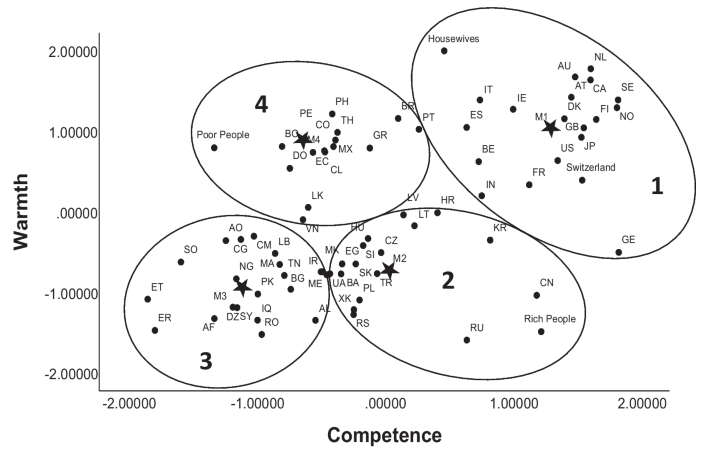
Slik kan man fortsette med mange forskjellige grupperinger som nevromangfold, psykiske lidelser, sosioøkonomiske/-kulturelle klasser og så videre. Poenget er bare at når man jobber med SCM, så kan det være litt misvisende å kun se på overordnede grupper i samfunnet – bak gjennomsnittet skjuler det seg mange viktige nyanser og kombinasjoner som må avdekkes med egne studier. De fleste som har jobbet i Helsevesenet vet eksempelvis at forskjellige sykdommer har forskjellig status, både å ha og å jobbe med – det er slikt som må finnes ut av separat for den generelle kategorien «syke» eller «pasienter».
For nerdene der ute, er det følgende spørsmålsbatteri som brukes til å måle varme og kompetanse (uavhengige variabler), samt da status (avhengig variabel):
