
Jakob Sverre Løvstad
CTO, Seema
6. august 2025
Et spørsmål jeg tidvis får når jeg underviser i stereotypier og fordommer, er «hvor kommer de fra?». Rent nevropsykologisk vil vi alltid oppleve en reaksjon på alt hjernen observerer som annerledes, men det betyr ikke dermed at man har en spesifikk overbevisning om gruppen man antar at den som er annerledes tilhører. Sagt enkelt: Bare fordi du hører en Ålesundsdialekt, gir det ikke automatisk mening å tenke «sunnmøringer er gjerrige». Man kunne jo tenkt mye annet, men det er altså en myte som finnes og dermed kobles det man hører (altså dialekten) til noe man «vet».
Så hvor kommer disse antagelsene fra?
Her er det nok en gang naturlig å henvise til Gordon Allport som beskriver fire sentrale (og heldigvis enkle) statistiske fenomener som leder til at man har visse typer tanker/meninger/følelser om forskjellige grupper. Husk at alt som nå følger handler om hvordan vi danner antagelser om grupper, men at hele poenget er at det ikke betyr at disse antagelsene er riktige. Dette er «eye of the beholder» type fenomener.
J-kurver med konform atferd:
J-kurver er en referanse til såkalte frekvenskurver formet som en «J» hvor man i en gruppe ser en atferd de aller fleste følger, slik som i følgende hypotetiske kurve for 17. mai-feiring i Norge (løst basert på en undersøkelse gjort av Dagbladet i 2013):
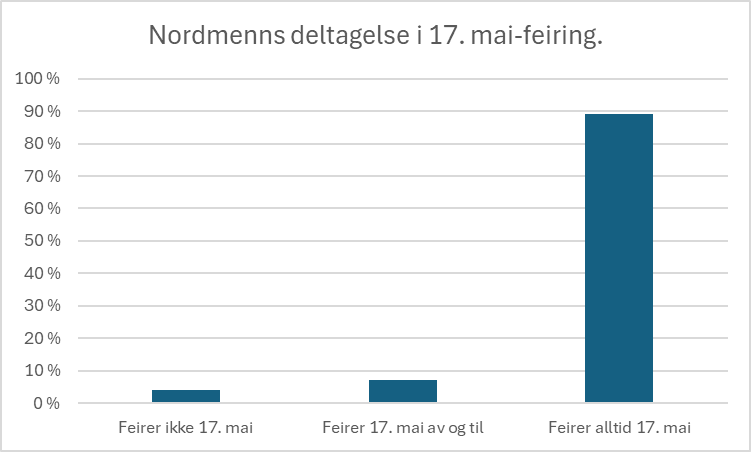
Hovedpoenget er at J-kurven beskriver hvordan atferden er innenfor en gitt gruppe. 17. mai-feiring er svært lite relevant for en greker som bor i Athen og ikke har noen relasjon til Norge. Så selve det at man er del av den konformitetsskapte atferden J-kurven beskriver, blir en identifikator. Så kan man da si i praksis at «nordmenn er sånne som som følger J-kurven for 17. mai-feiring». Og så skapes da en tanke om hva det er å være norsk i de utenforståendes øyne.
Sjelden nulldifferensial («rare-zero differential»)
Dette beskriver et fenomen der man i en gruppe har noen få som utøver en atferd eller har et trekk – som samtidig er ikke-eksisterende i andre grupper. Altså blir det for utenforstående en tanke om at en gruppe har noe ved seg, selv om det gjelder ganske få i gruppen. Et enkelt eksempel er skotter og bruk av kilt. Kilten er for de fleste noe man i Skottland kun bruker i spesielle anledninger (om i det hele tatt), men samtidig er det kun svært unntaksvis at plagget brukes av andre. Altså kan man få en tanke om at «skotter er sånne i kilt», selv om punktprevalensen til enhver tid er ganske lav – fordi den er nær null hos andre. Man får et noe fiktivt skille basert på unntaksvise fenomener.
Overlappende normalfordelinger
For en rekke egenskaper ved mennesker, ser vi at man får en normalfordeling som beskriver hvor mange som har en grad av hva enn det er vi måler. Vanlige eksempler er personlighet og kognitive evner. Og om man så deler opp disse målingene på eksempelvis kjønn, så vil man få overlappende normalfordelinger hvor det samtidig er en forskjell i gjennomsnitt og standardavvik. Altså noe slik:
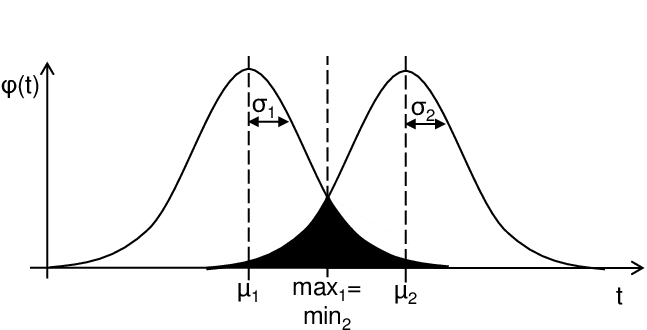
Om vi så ser på, bare for å ta noe, artikkelen «Gender Differences in Personality across the Ten Aspects of the Big Five» (Weisberg, DeYoung og Hirsh, 2011), vil man se en rekke differanser i personlighetstrekk. Som i flere andre studier ser man en høyere nevrotisisme hos kvinner enn menn (Cohens d ~ 0,39) og også høyere omsorg (Cohens d ~ 0,45), med noe tilhørende forskjell i kurtose. Da er det lett å komme opp med floskelen «kvinner er volatile og omsorgsfulle» – en tanke som har blitt brukt mye som kjønnsdifferensiator opp gjennom tidene.
Og slik blir normalfordelinger og effektstørrelser brukt til veldig forenklede myter om grupper i mange sammenhenger, uten å helt skjønne nyanser i statistikk eller atferdstilpasninger av trekkene.
Kategoriske forskjeller
I en del sammenhenger finner man rett og slett at det er flere/færre av noe i en gruppe versus en annen gruppe. Eksempelvis regner man med at prevalens av alkoholbrukslidelse i Norge er et sted rundt 5-8%, mens det i Russland regnes å være 7-12%. En slik forskjell kan bli en kilde til en måte å tenke forskjell mellom de to landene på, med tilhørende antagelser om befolkningsgruppene. Man får kanskje i Norge en tanke om russere som «Boris Jeltsin»-typer som aldri befinner seg langt fra en vodkaflaske, til tross for at prosentvis forskjell ikke per dags er enorm.
Oppsummert
Som jeg pleier å si, kommer stereotypier og fordommer fra et sted og kan være i varierende grad sanne og usanne. Gitt det statistiske utgangspunktet, må man alltid gå et par runder og undersøke «hva som egentlig er greia» når man hører om en gitt antagelse om en gruppe mennesker, og så vil man til gangs ende opp med et nyansert grunnlag for å diskutere hva enn det er som er en antatt gruppedifferensiator. Det viktige er å ha et kaldt sinn og se nøye på hva som egentlig er tilfellet, heller enn å få et overslag i ene eller andre retningen.