
Jakob Sverre Løvstad
CTO, Seema
9 February 2026
One of the most important models for understanding stereotypes and prejudices in a systematic way is the so-called "Stereotype Content Model", originally put together by Fiske, Cuddy, Glick and Xu. Furthermore, it has been tested and mapped in a number of different contexts - which is obviously important given that who one has stereotypes around and prejudices against varies from time phase to time phase and culture to culture (among other things). Such things are always relative.
In short, the model says that everything we think about various groups at a surface level can be seen as an expression of a) how warm/friendly/social people are considered to be, and b) how much expertise/how much agency they are considered to have. In simple terms, this is what gives groupings status in the eyes of others.
For Norway in particular, we have an overview of groups and their reputation dating back to 2015 (unfortunately no updates since then):
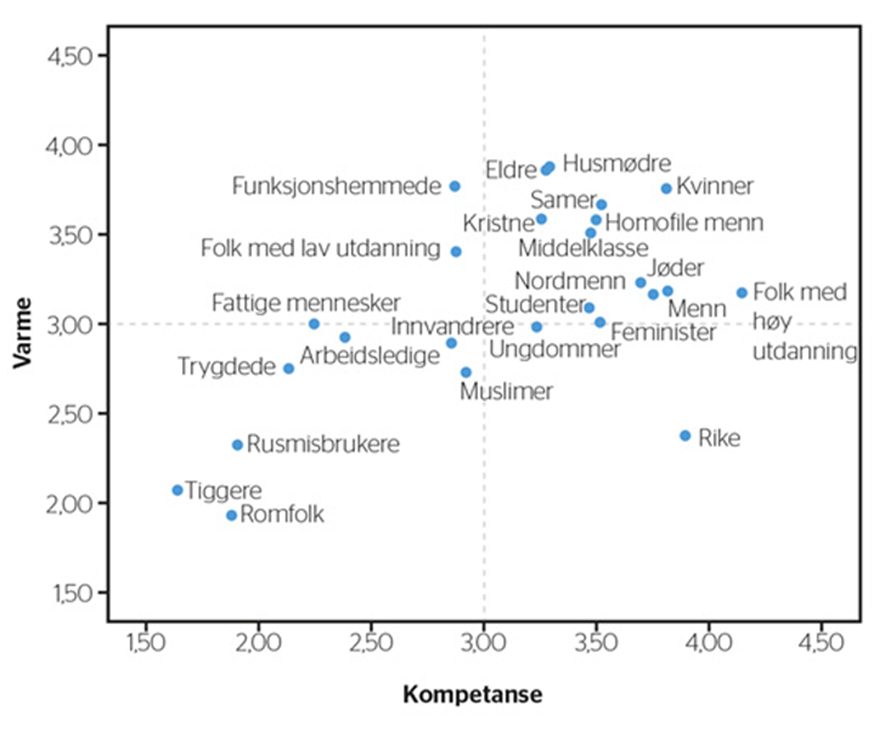
What we have emphasised to a lesser extent is that there are of course major variations within these groups in terms of how they are perceived. For example, the fact that "gay men" score well (high both heat and expertise) does not mean that all queers end up in the same box. A recent study from Sweden, for example, shows that at both the explicit (self-reporting) and implicit levels ("Implicit Association Test"; IAT), we have an equal distribution of different types of queer people (albeit with a slight difference in distribution), which makes it clear that subgroups are not viewed equally:
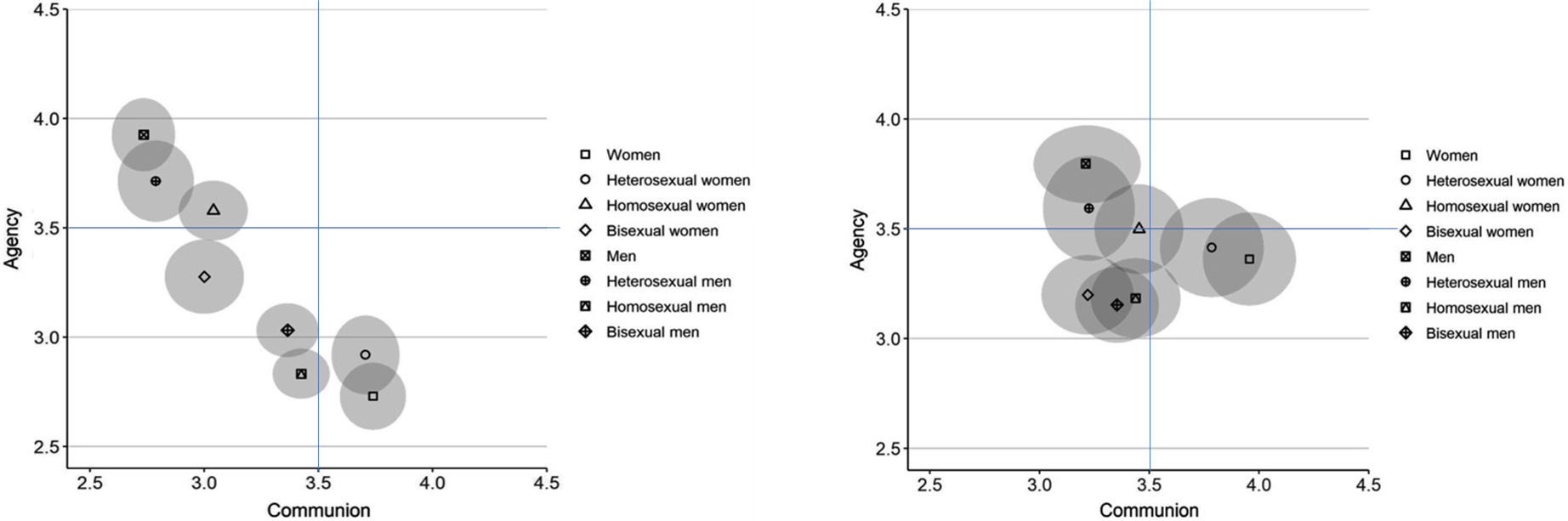
As a footnote, it is interesting that there is such a big difference on some of the points mentioned between Norway in 2015 and Sweden in 2021. Of course, this may be due to differences in the selection of participants for the study, but it's still worth considering.
In Switzerland in 2024, a small study was done on how students view other nationalities, with the following result, which is also interesting (note that "Poor People", "Rich People", "Housewives" are anchors/checks to see that the model generally reflects other studies of the same type):
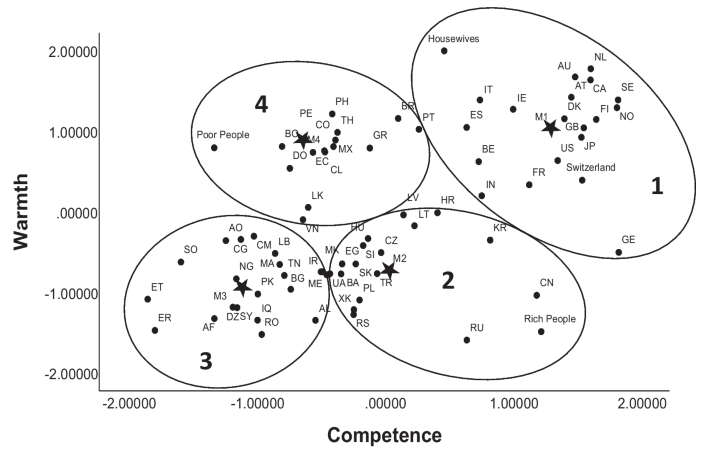
You can go on like this with many different groupings, such as neurodiversity, mental disorders, socio-economic/cultural classes and so on. The point is that when working with SCM, it can be a little misleading to only look at overall groups in society - behind the average, there are many important nuances and combinations that need to be uncovered with your own studies. For example, most people who have worked in the healthcare sector know that different diseases have different statuses, both to have and to work with - this is something that needs to be found out separately for the general category "sick" or "patients".
For the nerds out there, the following battery of questions is used to measure warmth and competence (independent variables), as well as status (dependent variable):
